IP会议电话回声消除器的设计及仿真
l 引言
IP电话(Voice Over IP,VolP)是指在因特网上实现实时传送语音信号的一种新型的电信业务,并且已从传统的Pc机与PC机连接发展到网关连接方式,它充分利用lnternet来传输语音数据,使得通信费用大大降低,从而取得了长足的发展。但是IP电话也存在一些弊端,比如语音质量比较差,影响IP电话语音质量的因素是多方面的,包括回声的影响,网络的时延和抖动,语音压缩编码等等,其中回声是最主要的影响。根据经验,如果语音的延时超过了50ms,那么人耳就可以鉴别出自己的回声。由于IP电话系统中语音信号要经过编码、压缩、打包等一系列处理,不仅造成了回声路径的延迟较大,而且延迟抖动也较大,使得总延时长达lOOms, 这就造成IP电话系统的回声非常严重。因此要提高IP电话的语音质量,就必须在语音传输的过程中进行消除回声的处理。鉴于此,国际电信联盟(ITU)也相应地制定了回声
消除的国际规范,如G.165、G.167和G.168等。目前为止,IP会议电话出现的众多回波抵消技术中,大多是基于最小均方(Least Mean Square,LMS)自适应算法的,但在实际应用
中,IP会议电话用于回波抵消的自适应滤波器需要安排很高的阶数,在这种情况下,采用LMS算法来实时实现自适应回波抵消是相当困难的。本文介绍了一种归一化快速块最小均方(Normalized Fast Block Least Mean Square,NFBLMS)算法,它是在快速块最小均方(Fast Block Least Mean Square,FBLMS)算法的基础上采用一阶AR模型的形式在自适应迭代过程中对输入信号的功率进行递推估计,然后对收敛因子进行归一化。该算法不仅能有效减小上述应用问题的计算复杂度,同时也能优化收敛速度,从而适用于IP会议电话的要求。
2 自适应回声消除实现原理
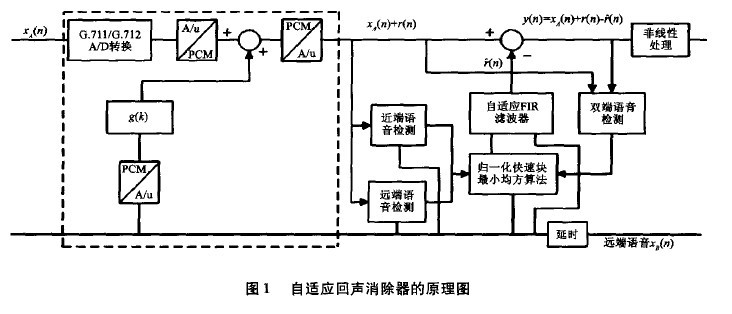
单向传输的自适应回声消除器的原理图如图1所示,图中虚线框是用冲击响应g(k)来模拟回声路径(Echo Path),XB(n)代表来自远端的语音信号,r(n)是经过g(k)模拟的回声路径而产生的不期望的回声,XA (n)是近端的语音信号。XA (n)+r(n)为近端语音信号叠加有不期望的回声。对回声消除器来说,接收到的远端语音信号 XB (n)作为一个参考信号,回声消除器根据它由自适应滤波器产生回声的估计值r^(n),将r^ (n)从近端带有回声的语音信号减去,就得到近端传送出去的信号y(n)= XA (n)+r(n)一r^ (n)。理想情况下,经过回声消除器处理后,残留的回声信号e(n)=r(n)一r^ (n)将为0,从而实现回音消除。另外,在自适应滤波器进行滤波和系数更新之前,要实时检测当前系统工作的语音模式。若检测为近端语音模式时,即 Xg(n)=0,就要停止自适应滤波器的滤波和系数更新功能,若检测为远端语音模式时,即 (n)=0,就要打开自话应滤波器的滤波和系数更新功能,若检测为双端语音模式,即近端用户和远端用户同时在说话时,要停止自适应滤波器的系数更新功能,只需要完成滤波。
2.1 自适应回声消除算法
由基本最小均方(Least Mean Square,LMS)算法的介绍可知 ,基本LMS算法的迭代公式为
W(n+1):W(n)+2 e(n) (n)
其 中,W(n)为滤波器权系数矢量, ( )为输入信号矢量,e(n)为误差信号。为了对付LMS运算量大的问题, 在LMS基础上提出了块处理LMS(BlockLMS. BLMS) 算法 。它与LMS算法不同的是:LMS算法是每来一个采样点就调整一次滤波器权值;而BLMS算法是每K采样点才对
滤波器的权值更新一次。这样BLMS算法的运算量就比LMS的运算量要小的多,但它的收敛速度却与LMS算法相同。在BLMS算法中,对于第 个数据块,可以对所有的可能值求乘积x(kL+i)e((kL+i )之和,并由此定义运行在实数据上的块LMS算法的权系数矢量更新公式为:
公式图
(2) 其中,收敛因子 μ包含了式(1)所示的基本LMS算法中2μ的作用。为了进一步推导的方便,将式(2)改写为W(k+1)=W(k)+ μ(k)
(3)式中,M×1维矢量 ( k)定义为 (k )=Σx (kl+i)e(kl+ i),L为滤波器的长度。另外,由数字信号处理中常用的重叠保留法和重叠相加法可知块自适应滤波器中的线性卷积和线性相关都可以利用FFT来快速实现 ,从而实现块LMS算法的快速算法,即快速块最小均方算法(Fast BlockLMS,FBLMS)。由上述理论可得滤波器权矢量频域的更新式为
W(kl+1)=w(k) +μFFT[KO]
(4)其中 (K )=IFFT [Xt (k)E(k)]的前M 个元素。由于FBLMS算法的稳定性,收敛性均与自适应滤波器的长度和输入信号的功率直接相关。一种能够优化收敛速度,同时维持与信号功率无关的重要方法称作归一化快速块最小均方(NFBLMS)算法。NFBLMS算法采用一阶AR模型的形式在自适应迭代过程中对输入信号功率进行递推估计,如下表声^ PX(n)=1/L ∑_(I=0)^(L-1)▒X2} (n—I ) ≅(1一1/L) ^ Px(n一1)+ 1/Lx2 (n)
(5) 由此可得NFBLMS算法滤波器权矢量更新公式为W(k+1)=W(K)+μ(n)FFT[∅(K)0]
(6)其中 μ(n)=α/dx ,它是滤波器长度 和输入信号功率X (n)功率归一化后的时变步长,a 为一个常数,px (n)是输入信号 X(n)在时刻n的功率估计。
2.2 自适应回声消除算法的主要性质
稳定条件:由最陡下降法的结果可知,FBLMS算法的稳定条件是
其中B 为块长度,A 为矩阵R 7 的最大特征值,由于(7)式中分母多了一个 ,所以FBLMS算法的稳定条件比LMS算法受到的限制较多。
收敛速度:
实际应用中总是希望自适应滤波器的收敛速度应尽可能快的跟踪未知系统,使正常通话开始后,通话者很快就听不到有明显的回声存在;当回声信道发生变化时,自适应滤波器应有快速的跟踪能力,尽量让通话者感觉不到信道发生了变化。由文献[4]知FBLMS算法平均收敛时间为
(8)
其中A 为矩阵R的特征值的平均值。计算复杂度:根据FBLMS算法和典型LMS算法的特点,对于每个N点数据块来说,FBLMS滤波器要求有五次2N点的FFvr运算和2次2N点的复数乘法。同时,2N点的FFT运算可以用N点FFT和N次复数相乘来实现。N点基2的FFT大约需要(N/2)log N~N次复数乘法。对于复数权矢量更新大约需要2N次。为了产生Ⅳ个输出点,LMS算法大约需要2.)、『2次实数乘法。假设一次复数乘法等效于4次实数乘法,则两者计算复杂度之比为复杂度之比=
3 ITU—T G.168一数字网络回声消除器
IrI1u就回声消除技术先后发布了一系列规范,分别包括电学回声和声学回声的消除。其中2007年1月公布的是关于数字网络回声消除器的最新规范。该建议书针对数字网络回声消除器提出了一般的设计要求,定义了相关的测试项目,以保证其能够在各种网络条件下提供足够的回声消除能力。该建议书覆盖了比G.165更加广泛的网络情况,包括话音、传真、残余的声学回声等。
3.1 基于G.168的复合信号源
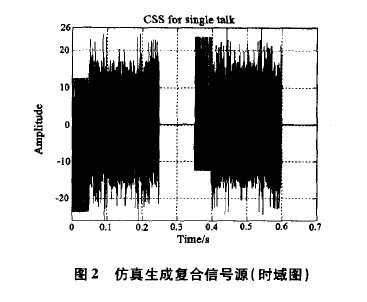
G.168中规定了一种特定的复合信号源(CompositeSource Signal,CSS),带限CSS是具有与话音类似的功率密度谱的信号,它可以仿真话音信号的特征,用它作测试信号可以测量回声消除器对话音信号的处理能力。由于信号的起始和终止都有明确定义,因此可以方便地测出同一方向上的切换时间,以及整个系统的切换和延迟时间。复合信号源有三部分组成,分别是语音信号(Voice Sound)、伪噪声信号(Pseudo Noise)、停顿(Pause)。MATLAB中生成的单端通话(single talk)复合信号源如图2所示,其中采样频率为441kHz,伪噪声信号由8192点傅里叶反变换生成。
3.2 回声路径的模拟
回声路径是由一个线性数字滤波器的冲击响应g( )来模拟实现。
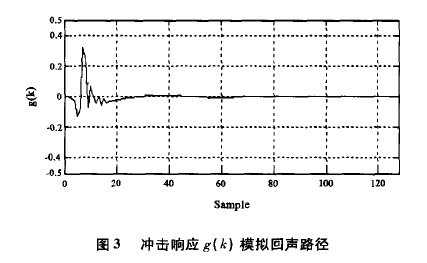
g(k)=(10 K)m (k一6)(i=1,2,⋯,8) (10)其中,i=1,2,⋯ ,8代表不同的回声路径模型,比例因子K 依赖于测试中的输入信号,6表示延时,目的是当g(k)不等于0时,它能被回声消除器日寄存器捕获,m (k)表示回声路径的各种发散特征。按照G.168规定,当输入信号为CSS或者白噪声时,选择i=1的回声路径模型,该回声路径模型是在模拟一种混合型网络情况下生成的。此时K1等于1.39×10-5,ERL等于6dB,m 1( K)代表短时发散。则冲击响应g(k)
如图3所示
4 仿真结果与分析
下面MATLAB中的仿真结果都是在远端语音模式下实现的。
4.1 计算复杂度
以CSS输人为例,当输入样本N等于32768时,由(9)式知复杂度之比为0.00241。另外,在MATLAB中也提供了‘ cputime’命令,它用来计算MATLAB进程运行的时间,例如,在算法运行之前执行starttime:eputime,运行算法之后执行cputime—starttime就可以得出CPU执行该算法所耗用的时间,为了减小CPU执行时的误差,对样本多次取值求期望,本次实验中自适应滤波器的长度L等于512,块的长度为32,实验得到的结果如图4所示
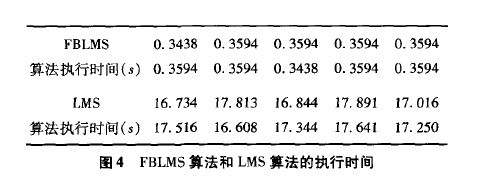
从计算效率来看,当块的长度Ⅳ等于滤波器长度工时,计算效率最高。由于本次实验选择的块长度小于滤波器长度,虽然这对于降低处理延迟是有利的,但在计算效率方面要小于L:Ⅳ 时的情况。从实验计算结果来看,即便N <£,FBLMS算法的复杂度远远小于LMS算法,由于NFBLMS算法相对FBLMS算法只是对收敛因子 进行归一化,这样做的目的是为了优化收敛速度,但在算法的复杂度方面,NFBLMS算法的计算量较之FBLMS算法稍有些增加。因此对于IP会议电话,综合各个性能指标,NFBLMS算法将是一个非常好的选择。
4.2 算法的收敛速度
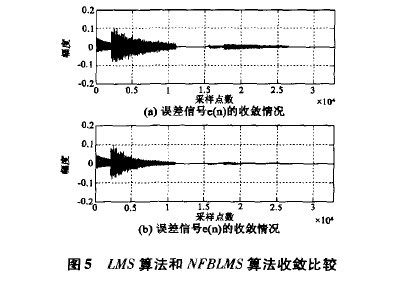
算法的收敛速度是反映回声消除器的性能一个重要指标。由(8)式知,收敛因子 决定算法的收敛速度, 越大,收敛速度越快,但/.t的选择不能太大,太大也会导致算法不稳定。图5(Ⅱ)为LMS算法的收敛特性,(b)为NFBLMS算法的收敛特性,初始收敛因子 =0.04,由图可知,经过肛归一化后,NFBLMS算法的收敛速度优于LMS算法。
4.3 回声返回损耗增益(ERLE)比较
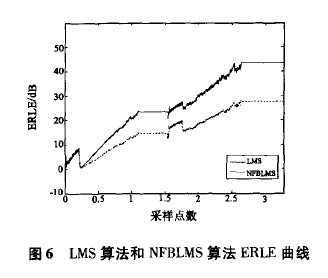
回声返回损耗增益(ERLE)是对回声消除器中回声电平改进的描述,实际总是希望ERLE越高越好。ERLE的定义如下Σd2(n— )ERLE(n)=lOlg J.—一 (11)Σ ( — )将(5)式代入上式,~ERLE( )=l。lg孝 ,即ERLE为期望信号与误差信号的功率之比。LMS算法和NFB! MS算法ERLE曲线如图6所示,由图可知,采用NFBLMS算法的ERLE要高于LMS算法,并且收敛速度也有所改善。
5 结束语
回声消除技术在IP电话中占有非常重要的地位,特别在IP会议电话中用于回声消除的自适应滤波器需要进行大量的运算。但实际应用中总是在算法复杂度、算法稳定性和收敛速度三者中做出选择,一般小的 值能获得更高的稳定性,但会导致收敛速度过慢。本文采用NFBLMS算法可以有效降低算法的复杂度,大大减轻了DSP开销,但由于受到算法稳定性的影响, 的选择不能太大,这样也就导致收敛速度不可能过快,尤其在双端语音模式下表现更为明显。因此要在双端语音模式下获得更快的收敛速度,还需对算法加以改进。